
8-bit Optimizers via Block-wise Quantization
很多claim快的方法,给给足够长的时间converge到最后都不如baseline,不知道这个怎么样
谢邀。上午学习了一下这篇文章,顺便看了看代码,在这里抛砖引玉一下~
本文主要是提出的一种对 optimizer 进行量化的方法,在不修改超参,不影响模型精度的情况下,把 adam / momentum 的状态量量化至 int8,从而缓解训练时的显存压力。
这个问题的背景大概是随着模型越来越大,尤其是预训练模型规模指数级增长,对显存的需求也就越来越高,而原始的 adam 优化器(因为感觉在 nlp 中 adam 比 sgd/momentum 用的更多一些,所以后文主要讨论 adam)对于每个参数都需要 m 和 v 两个 fp32 的参数,相当于每 1B 的参数都需要 8G 的存储空间,占了整体的很大一部分。所以如果能够把 optimizer state 量化下来,就能适当缓解显存的压力。
先要对优化器量化的流程做一个简单的介绍。一个常规的流程是这样的:
低精度优化器 --> 高精度优化器状态 --> 结合梯度更新参数 --> 重新量化回低精度参数毕竟直接少了 3/4 的信息,所以为了避免精度损失,作者主要提出了 3 个 trick。前两个是针对量化这个过程的,最后一个对 Embedding 结构的一个针对性调整。
作者把参数划分为了小 Block(在实践中使用的是每 2048 个参数一个 block),在进行量化的时候,按照 block 内绝对值最大的数对这个 block 进行归一化,使得所有参数都落在[-1, 1]这个范围。相较于之前的整个参数层一起归一,有 3 点好处:
- 经过观察,在正态分布下,绝对值很大的参数的比例会很少,所以一起归一会使得大多数参数变得很小,从而使得量化过程中的一些数字范围对应的 int8 没有被充分利用,导致更多的信息丢失。而以 block 为单位会使这个影响限制在 block 中。
2. 一般来说,1 中提到的不到 1% 的这些”大数“ 往往是(arguably)更重要的,而量化过程可以保证最大的数的精度没有损失,所以划分为多个 block 之后可以保证更多“大数”的精度,从而保留重要部分的信息。
3. 分成小 block 有利于显卡的并行计算,提升计算效率。
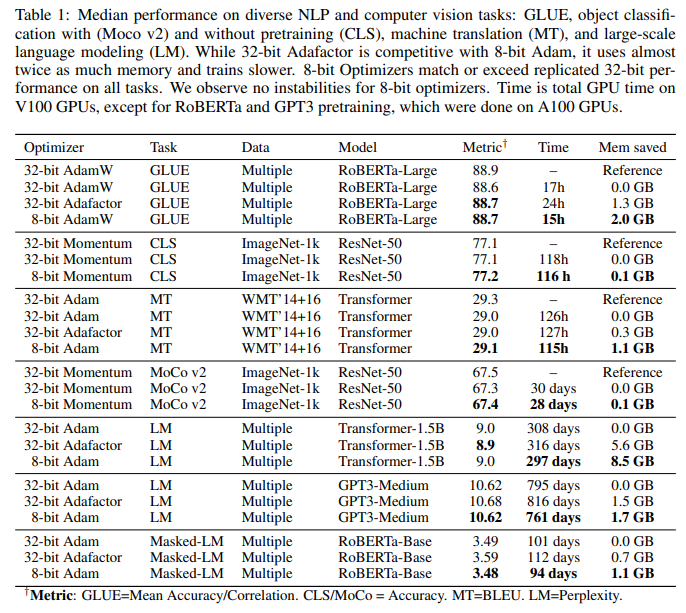
第二条则是调整量化映射的方式。从 fp32 转至 int8,一般不会直接截断 cast,因为往往较小的数需要保留更多的小数位上的信息。所以之前作者提出过 Dynamic Tree Quantization,就是把 int8 也表示为类似于 fp32/fp16 的形式,分为指数部分和小数部分,如下图。这个结构表示的是[-1, 1]之间的数,分为 4 小部分:
- 符号位;
- 又连续多少 0 表明起始位是 1e-n;
- 第一个标注为 1 的数为标注位,表示后面就是小数位了;
- 后面的地方就是表示的一个线性的数值,例如下图中后 4 位是 9,而最大值是 15,所以为 9/15。
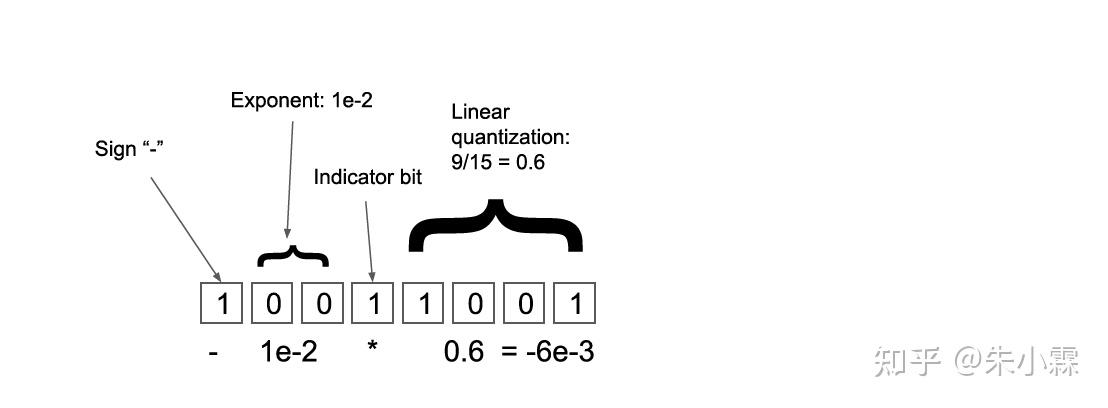
在本文中,因为观察到 adam 的 v 和 m 基本都在固定的 3~5 个数量级上,所以改成了固定的小数位数。并且因为 adam 的 v 项是恒正的,所以对于它去掉了指示符号的一位。
最后是一个对 embedding layer 的一个改进。在实验中,他们发现 emebddign layer 经常出现梯度溢出等问题,所以在 embedding 中多加了个 layer norm,并且调小了初始值。文章宣称这种方法对原先 fp32 的训练也有效果。
文章配了一个开源的 github,实现了高效版的 8bit Adam:
GitHub - facebookresearch/bitsandbytes: Library for 8-bit optimizers and quantization routines.我去简单看了一下里面的实现,主要有这样几点。
- 基本就是每个 optimizer 实现了几个 kernel,分别是 fp32 版,int8 w/o blockwise, int8 w blockwise,都是 inplace 运算。里面比较广泛地使用了 Nvidia 的 cub 库:https://github.com/NVIDIA/cub,用来做 load, store 和 reduce(用来求最大值)。
- 在做量化方面,正向的查表(int8 -> fp32)就是在 python 中预先做好表再传入 kernel 的,反向的是通过类似 2 分法的方式完成的,具体可以看一下
dQuantize和quantize_2D2 个函数。里面有配置一个随机的量化选项,我不太清楚这是干啥的...
有的朋友可能要问了,DeepSpeed 不都已经说了可以把 optimizer 移到 CPU 上去做了吗?那这个工作的意义在哪里呢?实际上,随着模型规模的不断提升,我们慢慢会把 CPU 内存也都用上,所以这个方法也可以起到降低 CPU 内存压力的效果。尤其是对于我们团队最新开源的派大星(PatrickStar),我们可以做到只把马上要进行计算的参数放在 GPU 上,其余部分全部动态 offload 至 CPU。那么这个工作可能也可以让派大星能支持的规模进一步提升(目前的规模基本在单张 V100,240G 内存,训练 12B 参数的模型)。对我们这个工作有兴趣的朋友,可以看看这里:
https://github.com/Tencent/PatrickStar以上。
原理什么的 @朱小霖 解释的很清楚了,看到文章作者不但提供了代码,还提供了适配各个版本cuda的pip包。再看用法,只用改一行代码就可以,说实在的人家都做到这个地步了,再不试试都不好意思了,于是抱着实践出真知的想法,我试了一下。。。
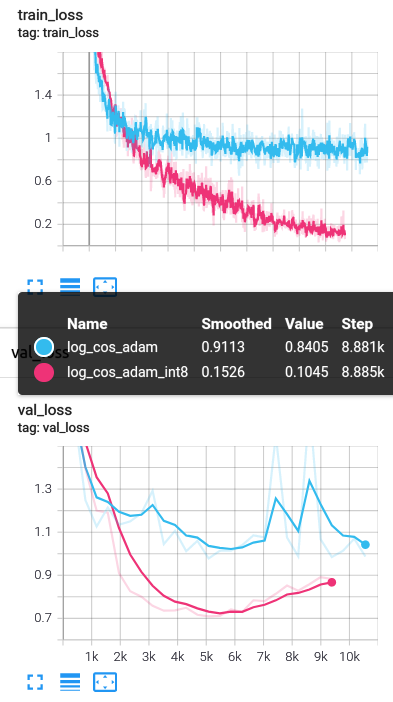
结果试出了奇奇怪怪的东西,用了这个int8的优化器,不但显存占用少了,连精度都提高了。。。不过显存节约有限,因为是CNN,参数量不大,而这个优化器节约的是参数的空间占用。所以应该比较适用于ViT或者MLP-Mixer之类参数特别多的东西,作者硬点的是NLP。不过用了反正不亏就是了。
不信大家看下面的图,粉红色是用的int8优化器,蓝色是用的PyTorch的,数据集是cifa10。两个训练曲线区别巨大,用int8优化器的那条线,训的那叫一个好,不是小好,是大好:
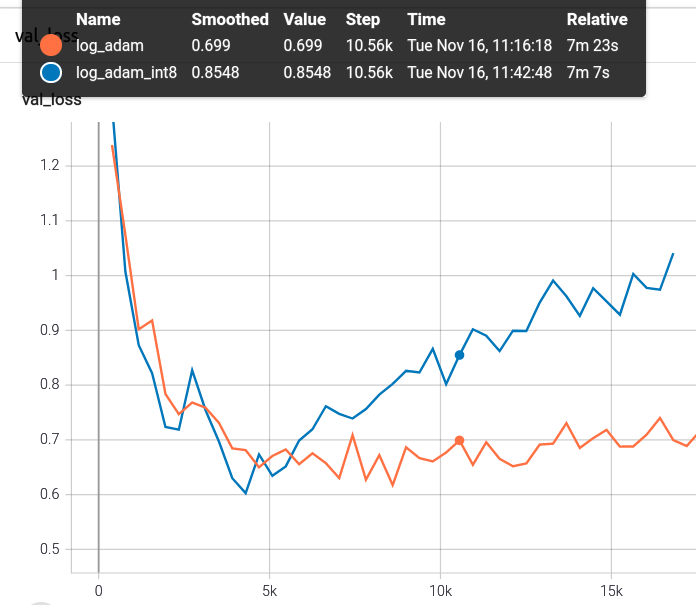
用小一点的学习率0.001又试了试,这次蓝色是int8,好像用int8更容易overfit,这次val的损失没之前大学习率小的那么夸张了,但过拟合之前还是稍微小点:
我反复检查了,应该是没错,代码在这里,大家可以试试,随机种子都定好了的,跑之前要装一下这个优化器:
pip install bitsandbytes-cuda111另外换int8优化器的时候把那两行注释掉的代码换一下就可以了:
import bitsandbytes as bnb
import torch
from torch import nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import random
from torchvision import models
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
torch.manual_seed(0)
random.seed(0)
np.random.seed(0)
batch_size=128
epochs=200
# we will apply the same transforms as described in the paper
train_transform=transforms.Compose(
[transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261))])
val_transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261))])
trainset=torchvision.datasets.CIFAR10(root='https://www.zhihu.com/question/cifar10', train=True,
download=True, transform=train_transform)
train_dataloader=torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=8)
testset=torchvision.datasets.CIFAR10(root='https://www.zhihu.com/question/cifar10', train=False,
download=True, transform=val_transform)
val_dataloader=torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=8)
classes=('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
iter=0
model=models.resnet34(num_classes=10).cuda()
criterion=nn.CrossEntropyLoss()
#Uncomment to use the int8 Optimizer
#logger=SummaryWriter(log_dir="log_adam_int8")
#optimizer=bnb.optim.Adam8bit(model.parameters(), lr=0.01, weight_decay=0.0005)
logger=SummaryWriter(log_dir="log_adam")
optimizer=optim.Adam(model.parameters(), lr=0.01, weight_decay=0.0005)
loss_plot_name='loss'
train_loss_list='train_loss'
val_loss_list='val_loss'
# training
def train(model, trainloader, optimizer, criterion):
global logger
global iter
model.train()
print('Training')
# we will use this list to store the updated learning rates per epoch
lrs=[]
train_running_loss=0.0
iters=len(trainloader)
counter=0
for i, data in tqdm(enumerate(trainloader), total=len(trainloader)):
counter +=1
image, labels=data
image=image.cuda()
labels=labels.cuda()
optimizer.zero_grad()
outputs=model(image)
loss=criterion(outputs, labels)
loss.backward()
optimizer.step()
train_running_loss +=loss.item()
logger.add_scalar("train_loss", loss.item(), iter)
logger.add_scalar("lr", optimizer.param_groups[0]["lr"], iter)
iter +=1
epoch_loss=train_running_loss / counter
return lrs, epoch_loss
# validation
def validate(model, testloader, criterion):
model.eval()
print('Validation')
val_running_loss=0.0
counter=0
for i, data in tqdm(enumerate(testloader), total=len(testloader)):
counter +=1
image, labels=data
image=image.cuda()
labels=labels.cuda()
outputs=model(image)
loss=criterion(outputs, labels)
val_running_loss +=loss.item()
epoch_loss=val_running_loss / counter
return epoch_loss
# start the training
train_loss, val_loss=[],[]
learning_rate_plot=[]
for epoch in range(epochs):
print(f"[INFO]: Epoch{epoch+1}of{epochs}")
lrs, train_epoch_loss=train(model, train_dataloader, optimizer,
criterion)
val_epoch_loss=validate(model, val_dataloader, criterion)
logger.add_scalar("val_loss", val_epoch_loss, iter)
train_loss.append(train_epoch_loss)
val_loss.append(val_epoch_loss)
learning_rate_plot.extend(lrs)
print(f"Training loss:{train_epoch_loss:.3f}")
print(f"Validation loss:{val_epoch_loss:.3f}")
print('------------------------------------------------------------')我还用自己的toy数据集跑了一下,结果是没有变差也没有变好,基本是是一样的,就不放了。
Update 2021/11/16
2080Ti的从源码编译成功并且运行成功了,看上去好像是服务器自带的cuda没装nvcc
(题外话吐槽一下现在组里服务器系统好像都是厂家直接装的 然而不知道他们怎么装的显卡驱动 cuda是缺胳膊少腿的 驱动也是刚到cuda10.1最低要求的…… )
于是自己在用户目录下面装了一个cuda 然后可以编译成功 现在在两张2080Ti上跑albert-xxlarge,看上去配了fairscale的FSDP以后最大显存没太大变化,但是backward的时候可以少很多显存(可能是说albert的显存瓶颈主要在前向上?)
TeslaT4上没成功,好像是服务器c++编译器的版本问题…… 好吧
做了简单的实验 模型是albert-xxlarge-v2-snli_mnli_fever_anli_R1_R2_R3-nli 数据集是ReClor 一个做逻辑推理的数据集 时间原因跑了43 44 两个种子
seed=42
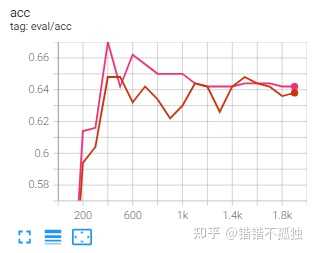
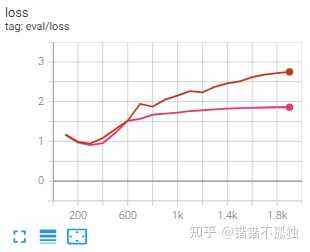
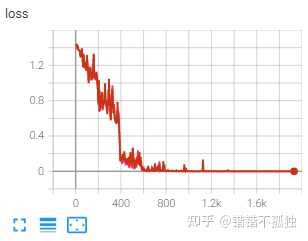
训练时间对比 5h 12min (baseline) / 5h 8min (8bit training)
seed=43
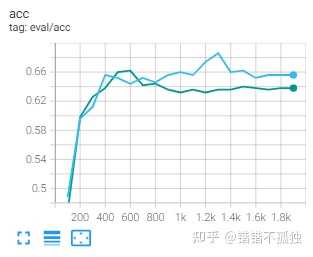
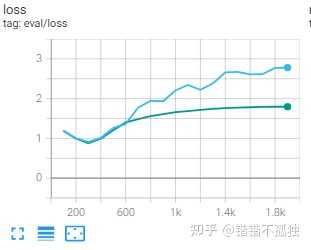
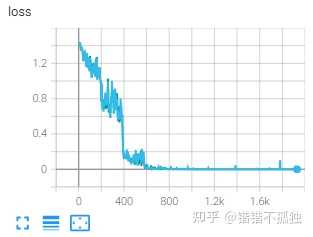
训练时间对比:5h 0min (baseline) / 5h 6min (8bit training)
总结下来感觉emmm 显存节省聊胜于无 时间上好像也不明显 至于效果 感觉影响的确实不是很大 主要是误差带来的噪声可能产生了一定的波动
不过我觉得可能也和albert和数据集本身有关系(训练到最后阶段训练集loss都接近0了……) 后续有时间可以试试roberta 或者预训练之后的效果
之前正发愁怎么把albert-xxlarge塞进单张2080ti来着 看到了这个就想试试
不过发现TeslaT4 / 2080Ti /TITAN XP 都没法成功安装 然后把cudatoolkit从10.1升级到11.3之后成功安装了(此时已经和服务器编译的cuda版本不一致了)但是没法正常backward
已经提了issue 之后可能试试从源码编译
该用adam还是adam
根本没人跟进
说明很多claim肯定有问题

